技術前沿:台積電CoWoS 封裝A1
封裝的未來變得模糊 – 扇出、ABF、有機中介層、嵌入式橋接 – 先進封裝第 4 部分
2.1D、2.3D 和 2.5D 先進封裝的模糊界線。在 IMAPS 2022 上,展示了該領域的許多進步,先進封裝產業的未來非常活躍。簡單回顧一下,目前有四大類先進封裝。
3D = 主動矽堆疊在主動矽上-最著名的形式是利用台積電的 SoIC CoW 的 AMD 3D V-Cache和利用台積電的 SoIC WoW 的 Graphcore IPU BOW。
2.5D = 主動矽堆疊在被動矽上-最著名的形式是使用台積電 CoWoS-S 的帶有 HBM 記憶體的 Nvidia AI GPU和使用英特爾 Foveros 的英特爾 Meteor Lake CPU。
扇出 RDL(環氧模塑膠層壓板)—最著名的形式是台積電的 InFO,用於蘋果的 A 系列、S 系列和 M 系列晶片、ASE FoCoS 和 Amkor WLFO。面板層正在由多家公司開發。
積層 ABF 基板(銅芯覆有味之素積層膜層和 RDL 層)– 最著名的形式是英特爾和 AMD PC 和資料中心晶片。

在大多數先進封裝中,仍使用積層 ABF 基板。這些基板被稱為混合基板。
先進封裝的另一個模糊之處是工程師經常使用「有機基板」這個詞。 ABF 和核心扇出都含有有機環氧化學物質。
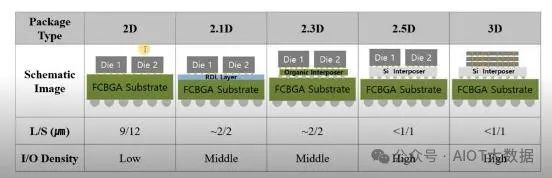
2.5D 到 3D 的分類看似簡單,但封裝種類的排列組合卻非常多,模糊了 2.3D 和 2.1D 之間的界線。此外,隨著 2.3D 和 2.1D 封裝功能的發展,2.5D 的市佔率將逐漸下降。

英特爾的 EMIB 是在 ABF 基板的腔體內放置矽橋。其主要目的是避免使用昂貴的矽中介層,並使封裝超出光罩極限。 EMIB 在技術上不是 2.5D 封裝,但它確實帶來了許多所謂的好處。與純 2.5D 矽中介層或高密度扇出相比,它在成本和性能方面如何?未來幾代產品尚無定論,但第一代產品並不佔優勢。

AMD 的 MI250X GPU(如上註)和 Apple 的 M1 Ultra 是同一產品中多種封裝類型的範例。 GPU 晶片和每個 HBM 之間沒有使用矽中介層連接,而是有矽橋。帶有嵌入式橋的扇出類似於英特爾的 EMIB,但製造流程完全不同,扇出 RDL 與累積基板。
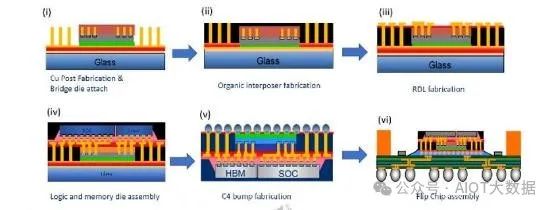
對於 MI250X,兩個獨立的扇出 RDL 組件與矽橋和 GPU/HBM 封裝在大型 ABF 基板的頂部。
雖然由於盡量減少使用昂貴的矽中介層,理論上這種方法的成本較低,但與傳統的 2.5D 矽中介層相比,產量損失的可能性更高。
扇出 RDL 並非單一製程。它可採用多種不同類型的材料建造。此外,它可以是 RDL 優先或 Chip 優先流程。
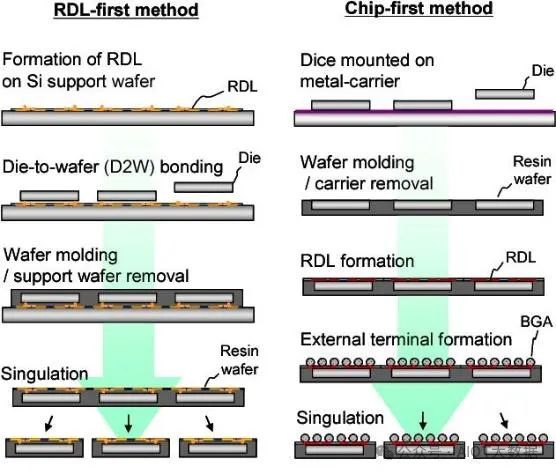
無論扇出 RDL 採用先 RDL 或先 Chip 製程,在放置晶片之前都無法測試完成的混合基板。如果採用扇出到基板的黏合工藝,可能會遺失好的晶片。儘管扇出 RDL 理論上成本較低,尤其是面板級扇出,但產量損失是繼續使用矽中介層的主要原因。由於扇出 RDL 材料、累積基板和矽之間的熱膨脹係數 (CTE) 不匹配,這些產量問題可能會延伸到基板翹曲。
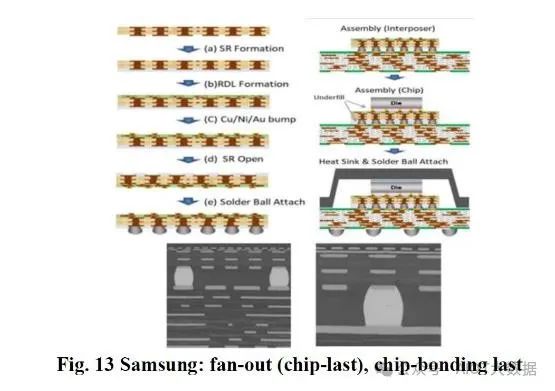
三星、新光、欣興、矽品和台積電一直在研究封裝工藝,首先製造扇出型 RDL;然後將扇出型 RDL 粘合在積層 ABF 基板上。然後對黏合的混合基板進行測試,最後將晶片黏合到其上。這稱為扇出型(RDL-First 或 Chip-Last),最後晶片黏合。每家公司都有自己的調整,有些公司使用有機或無機材料。擁有已知的用於先進封裝的優質基板可提高組裝產量和物流,這是巨大的優勢。
資料中心和 PC 產業傳統上採用將已知良好基板與已知良好晶片相匹配的供應鏈。如果可以經濟高效地完成,則先進行 RDL/最後進行晶片接合是首選的封裝方法。
與扇出型(最後晶片或 RDL 優先)製程相比,扇出型(先晶片)製程的 IC 整合更簡單,成本更低。問題是,先晶片意味著封裝良率會降低更多已知良好的晶片。隨著業界轉向更昂貴的製程技術,這種封裝良率損失繼續成為封裝製程成本成長的主要因素。此外,扇出型(最後晶片)整合還有其他優勢,例如晶片尺寸更大、封裝尺寸更大、晶片移位問題更少,以及 RDL 的金屬 L/S 更精細。 L/S 是線距,指的是金屬互連的寬度和它們之間的空間。
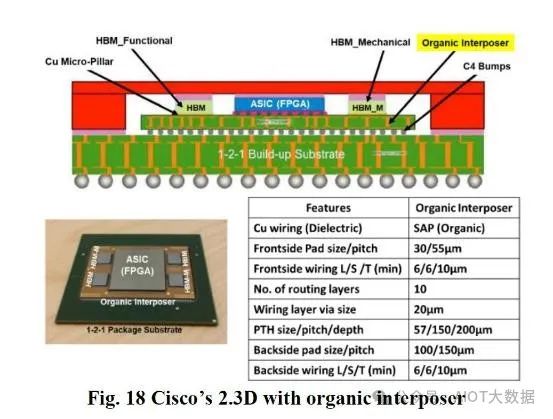
此外,非扇出技術也不斷改進。思科已經展示了與無芯有機基板相關的研究。製造這種有機中介層的主要製造步驟與積層封裝基板相同,但沒有銅芯。與帶芯的標準積層 ABF 基板相比,思科展示了 10 個佈線層,其 L/S 密度更高。
如今,積層 ABF 基板的 L/S 密度高達 10 微米;思科的研究表明,有機基板的 L/S 可降至 6 微米。核心扇出市場的 L/S 在 15 微米範圍內。一些先進的扇出,例如AMD 的 RDNA 3 GPU和聯發科網路處理器,可降至 2 微米 L/S。 EMIB 在第一代達到 5 微米 L/S,據傳未來幾代將達到 2 微米 L/S。
隨著 ABF 基板的改進,核心扇出和 HD 扇出市場在行動應用之外逐漸受到蠶食。關於介電材料,光成像介電材料 (PID) 目前能夠達到更細的間距。儘管如此,ABF 在表面變化方面仍具有許多優勢,正如 Unimicron 所展示的那樣。

Unimicorn 希望堅持使用改進的 ABF,因為這是他們的核心競爭力。細間距無芯 ABF 堅持其現有的業務模式,即提供已知良好的(混合)基板。它們可以實現 3 微米 L/S,表面變化更好,從而可以擴展到更高的層數。他們的無芯 ABF 基板可能與目前先進的扇出製程非常有競爭力。它是在面板上完成的,因此與晶圓級相比具有競爭力,並且接近未來的面板扇出製程。雖然它僅限於 3 個 RDL 層,但擴展到更多層的路徑比扇出 RDL 更容易。
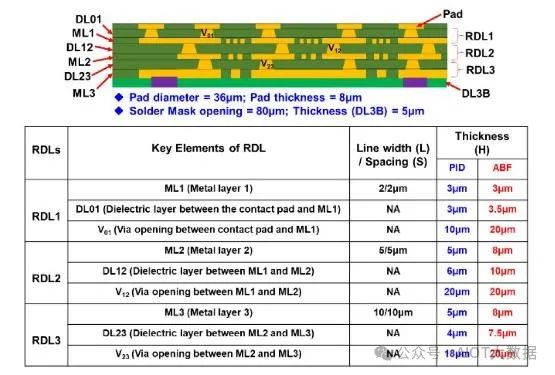
無芯 ABF 基板較厚,這對於行動應用來說可能是一個問題,但對於高性能應用來說,可靠性和性能應該會更好。
在追求 L/S 時,Amkor SLIM 和 ASE SPIL NTI 可以實現 0.4 微米和 0.5 微米。兩者都僅限於第一層上的這些精細間距。
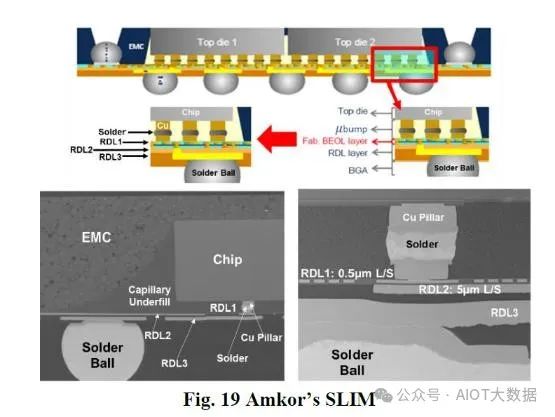
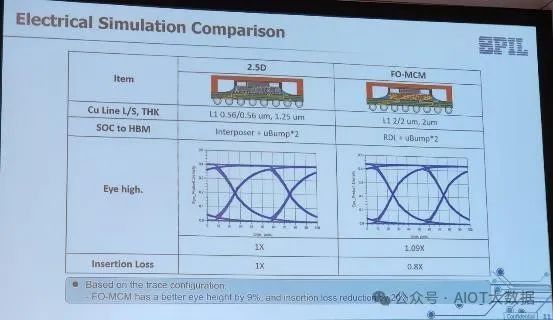
ASE SPIL 表示,其扇出型 RDL 的性能優於 2.5D 高級封裝,可用於將 HBM晶片連接到 SOC。 ASE SPIL 聲稱其眼高更佳,損耗減少更少,從而允許更高的訊號速率和更低的噪音通過封裝。
雖然積層 ABF 基板仍將是先進封裝市場的基礎,但隨著向無芯基板的過渡,它們的性能和密度正在提高。此外,這些基於 ABF 的基板可以達到更高的層數,正如思科所展示的那樣,這要歸功於 Unimicron 所展示的卓越表面變化特性。在許多用例中,ABF 基板正在趕上並超越扇出型 RDL。
隨著 RDL 扇出製程逐漸進入先前僅由 2.5D 中介層所佔據的應用領域,成本和產量也是至關重要的因素。採用矽橋的扇出製程開始逐漸普及,但無需使用矽橋即可將 ASIC 與 HBM 整合的新製程也即將投入生產。扇出製程和 ABF 基板方面的這些進步正在迅速模糊先進封裝之間的界限。
在評估 2.1D 至 2.5D 領域的先進 IC 封裝時,需要考慮多個變數。焊盤間距、L/S 和層數是重要因素,但可靠性、翹曲問題、封裝成本、產量和封裝尺寸也在考慮範圍內。未來,在標準積層 ABF 基板頂部封裝無芯 ABF 基板的混合基板可能是某些用例的最佳選擇。在其他情況下,在標準積層 ABF 基板頂部封裝晶片優先扇出 RDL 可能是另一個用例的最佳選擇。隨著晶片數量和類型的異構集成多樣性,封裝所涉及的權衡變得越來越難以評估。
混合鍵結流程 – 先進封裝第五部分
BESI、EV Group、AMAT、TEL、ASMPT、SET、芝浦、SUSS Microtec
混合鍵結將成為自 EUV 以來半導體製造領域最具變革性的創新。事實上,它對設計流程的影響甚至比 EUV 本身更大,從封裝架構到單元設計和佈局。 IP 生態系統將發生巨大變化,製造流程也將如此。 2D 晶體管縮小的時代將繼續,但速度會有所放緩,而混合鍵合將帶來一個新時代,晶片設計師將以 3D 思維思考。
隨著這首充滿炒作的歌謠的結束,我們應該注意到,將混合鍵合大規模推向市場面臨著許多重大的工程和技術挑戰,因為目前它只限於少數 AMD 晶片、CMOS 影像感測器和一些供應商的 3D NAND。這種轉變將重塑供應變化和設計流程。
我們將從基礎開始講解混合鍵合的高階方面,包括製程、工具、設計用例、挑戰、晶圓晶片與晶圓晶片的成本。我們還將介紹我們專有的採用模型,該模型涵蓋了各個市場(行動裝置、客戶端 PC、資料中心 CPU、AI 加速器、HBM 等)的使用情況、工具要求和數量,以及到 2020 年末的公司級採用情況。
在封裝史上,上一次重大的典範轉移是從引線接合到倒裝晶片。從那時起,更先進的封裝形式(如晶圓級扇出和 TCB)一直是同一核心原理的漸進式改進。這些封裝方法都使用某種帶有焊料的凸塊作為矽片與封裝或電路板之間的互連。這些技術可以一直縮小到約 20 微米間距。
到目前為止,我們在多部分先進封裝系列中討論的主要封裝類型和製程都是 220 微米到 100 微米規模,並且主要使用焊料作為各種晶片銅互連之間的介質。要進一步擴大規模,需要進行另一種範式轉移:採用混合鍵結的無凸塊互連。混合鍵合的規模超過 10 微米互連間距,並計劃向 100 奈米等級發展,並且不使用任何具有更高電阻的中間體,例如焊料。
相反,不同晶片或晶圓之間的互連直接透過銅通孔連接。直接銅連接意味著在向各個晶片發送資料時電阻會大大降低,因此功耗也會降低。再加上連結數量的數量級增加,設計需要徹底重新思考。
回顧第 1 部分,先进封装的重点是什么?我们可以看到,封装技术的进步旨在实现更高的互连密度(单位面积上更多的互连),减少走线长度以降低延迟和每比特传输的能量。我们可以看到混合键合如何解决这两个问题:显著缩短走线长度,因此延迟尽可能低,而无需在芯片上,在某些情况下比芯片上的全局舍入更短,并且互连间距可以远低于 10 微米以增加密度。
混合鍵結到底是什麼?
混合键合用于芯片的垂直(或 3D)堆叠。混合键合的显著特点是无凸块。它摒弃了基于焊料的凸块技术,转而采用直接铜对铜连接。这意味着顶部芯片和底部芯片彼此齐平。两个芯片都只有铜垫,而不是凸块,可以缩小到超细间距。没有焊料,因此避免了与焊料相关的问题。

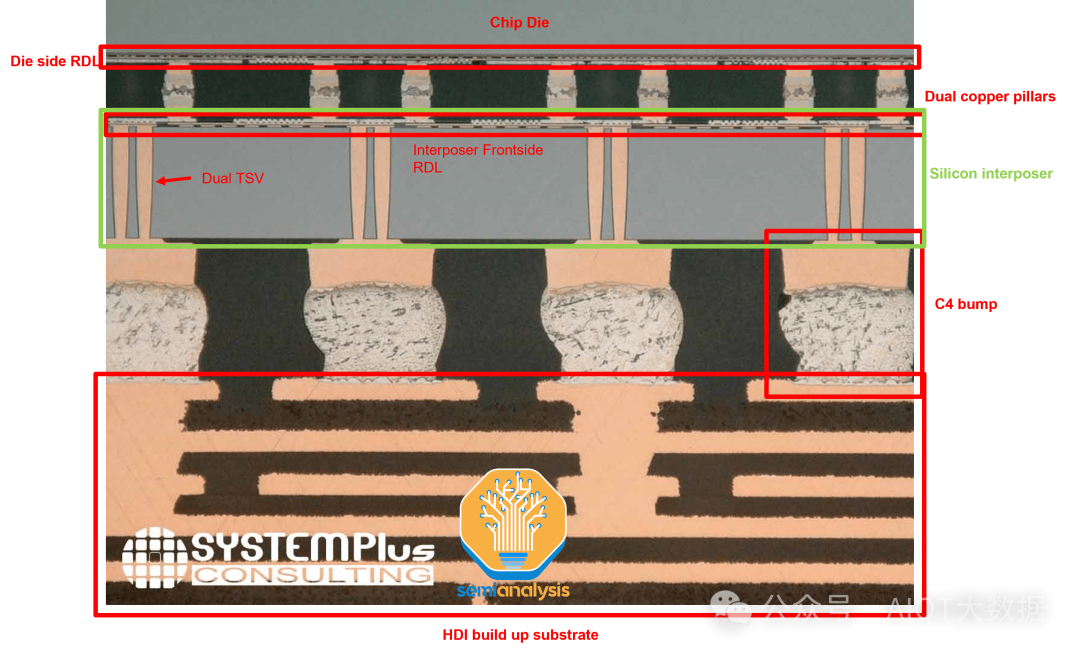
從上圖中,我們可以看到 AMD 3D V-Cache 的橫截面,它採用了台積電的 SoIC-X 晶片到晶圓混合鍵合。頂部和底部矽之間的鍵結界面是混合鍵結層,位於矽晶片的金屬層頂部。混合鍵結層是一種電介質(現在最常見的是 SiO 或 SiCN),上面有銅墊和通孔,間距通常小於 10 微米。
電介質的作用是隔離每個焊盤,使焊盤之間不會發生訊號幹擾。銅焊盤透過矽通孔 (TSV) 連接到晶片金屬層。 TSV 需要將電源和訊號傳輸到堆疊中的另一個晶片。由於底部晶片「面朝下」放置,因此需要這些通孔連接頂部晶片上的金屬層,穿過電晶體層到達底部晶片上的金屬層。
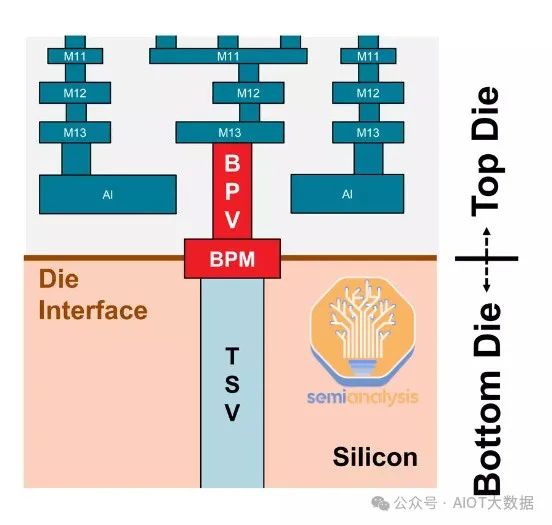
訊號正是透過這些銅墊來實現晶片間通訊。之所以稱之為「混合」鍵合,是因為它是電介質-電介質鍵結和直接銅-銅鍵合的組合。鍵合界面之間無需使用額外的黏合劑或材料。
關鍵製程條件
與先前的基於凸點的互連相比,引入了一系列全新的技術和製程挑戰。為了實現高品質的鍵合,對錶面光滑度、清潔度和鍵結對準精度有非常嚴格的要求。我們將首先描述其中一些挑戰,因為流程是圍繞緩解這些挑戰而設計的。記住這些將幫助您更好地理解流程為何如此,以及不同方法的優缺點。
顆粒和清潔度
在任何有關混合鍵合的討論中,都會提到顆粒。這是因為顆粒是混合鍵結中產量的敵人。由於混合鍵合涉及將兩個非常光滑和平坦的表面齊平地粘合在一起,因此鍵合界面對任何顆粒的存在都非常敏感。
僅 1 微米高的顆粒就會導致直徑 10 毫米的鍵結空隙,從而導致鍵合缺陷。對於基於凸塊的互連,由於使用了底部填充或非導電膜,因此設備和基板之間總是會存在間隙,而間隙可以容忍一些顆粒。
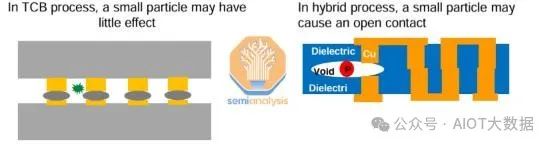
保持清潔至關重要,而且非常具有挑戰性。晶圓切割、研磨和拋光等許多步驟都會產生顆粒。任何類型的摩擦也會產生顆粒,這是一個問題,尤其是因為混合鍵合涉及機械拾取晶片並將其放置在其他晶片之上。來自晶片鍵合頭和晶片翻轉器的工具中有很多運動。顆粒是不可避免的,但有幾種技術可以減輕產量影響。
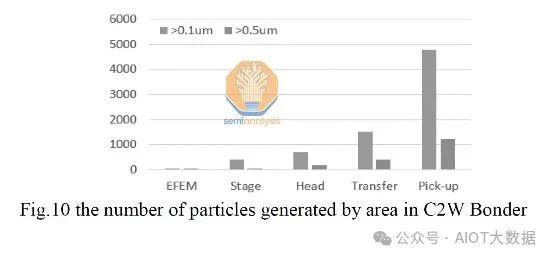
當然,晶圓清洗是定期進行的,以去除污染物。然而,清洗並不完美,無法一次性去除 100% 的污染物,因此最好從一開始就避免污染物。混合鍵結所需的無塵室比其他形式的先進封裝所需的無塵室先進得多。
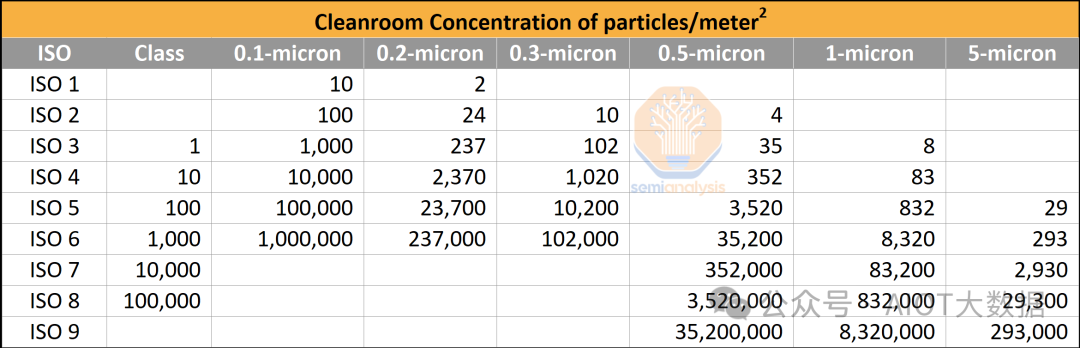
因此,混合鍵合通常需要 1 級 / ISO 3 級或更高級別的無塵室和設備。例如,台積電和英特爾正在全力實現 ISO 2 級或 ISO 1 級。這是混合鍵合被視為「前端」製程的一個主要原因,即它發生在類似晶圓廠的環境中,而不是傳統封裝廠商(OSAT)的環境中。鑑於清潔度要求的升級,OSAT 很難進行混合鍵合。如果 OSAT 想要參與混合鍵合,大多數 OSAT 都需要建造更新、更先進的潔淨室,而台積電和英特爾等公司可以使用較舊的晶圓廠或按照與現有晶圓廠類似的標準建造。
混合鍵結的製程也涉及許多傳統上僅由晶圓廠獨家使用的工具。 ASE 和 Amkor 等外包裝配和測試公司 (OSAT) 在化學氣相沉積 (CVD)、蝕刻、物理氣相沉積 (PVD)、電化學沉積 (ECD)、化學機械平坦化 (CMP) 和表面處理/活化方面的經驗相對較少。
清潔度要求和工具增加導致成本大幅增加。與其他形式的封裝相比,混合鍵合製程並不便宜。我們將在下面介紹工藝流程。
平滑度
混合鍵結層的表面光滑度也極為關鍵。 HB 介面同樣對任何類型的表面形狀都很敏感,這會導致空洞和無效鍵結。一般來說,電介質的表面粗糙度閾值為 0.5nm,銅墊的表面粗糙度閾值為 1nm。為了達到這種光滑度,需要進行化學機械平坦化 (CMP),這是混合鍵結的關鍵製程。
拋光後,整個流程都需要保持這種光滑度。應避免任何可能損壞該表面的步驟,例如粗暴清洗。甚至晶圓分類探測也需要調整,以免損壞表面。
晶圓到晶圓 (W2W) 或晶片到晶圓 (D2W)
首先,討論一下 W2W 或 D2W。混合鍵合可以透過晶圓對晶圓 (W2W) 或晶片對晶圓 (W2W) 製程完成。 W2W 意味著將兩個製造好的晶圓直接鍵結在一起。 W2W 提供更高的對準精度、產量和鍵結良率。鑑於其相對容易,目前絕大多數的混合鍵結都是透過 W2W 完成。
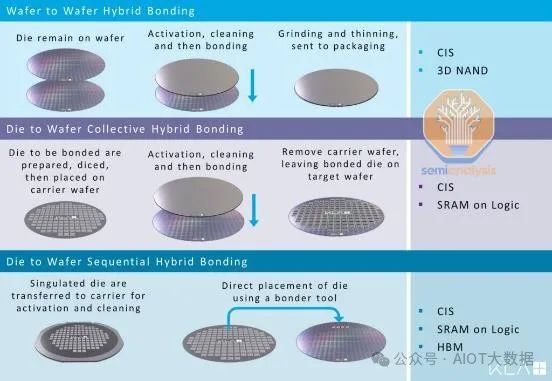
W2W 鍵結良率較高的原因是對準和鍵結步驟是分開的。在 W2W 工具中,有一個單獨的腔室用於執行對準。一旦頂部和底部晶圓對準,它們就會被移入鍵合腔室(處於真空中),在那裡用一點力將它們壓在一起,大約 20 分鐘後,初始預鍵合就形成了。
W2W 的關鍵在於它是一種更清潔的工藝,步驟更少。在對準和鍵合之前,可以清潔晶圓以去除大部分顆粒。晶片分離(顆粒污染源)僅在鍵結後發生。由於它是晶圓級工藝,因此對準步驟也有更多的時間,因此更長的對準時間不會像晶片級工藝那樣損害產量。
腔內也沒有太多移動,因此腔內污染物較少。目前,W2W 鍵合機可以實現 50nm 以下的對準精度。 W2W 鍵合已經是一種成熟的工藝,而且成本並不高。證據是,我們看到它在大眾市場產品中被廣泛採用,例如 3 層影像感測器和 NAND。
W2W 鍵合很棒,但一個主要限制是無法進行晶圓分類以選擇已知良好晶片 (KGD)。這會導致不良結果,即有缺陷的晶片與良好晶片鍵合,浪費優質矽片。
有鑑於此,W2W 用於良率較高的晶圓,這通常意味著較小的設計。在下圖中,我們可以看到 W2W 和 D2W 的晶片面積與成本之間的關係。晶圓尺寸越小,W2W 越便宜,因為晶圓良率會更高。然而,隨著晶圓尺寸的增加,W2W 成本曲線會變得更加陡峭,這主要是由失去的良品晶圓的成本所致。隨著晶片尺寸的增大,每個晶圓的良品晶圓比例會減少,從而導致有缺陷的晶圓和良品晶圓的結合更多。
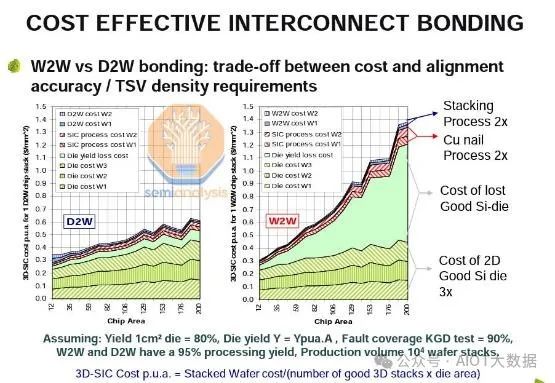
我們可以看到,W2W 用於具有高產量的較小晶片:CMOS 影像感測器、3D NAND,以及到目前為止僅用於Graphcore Bow IPU的邏輯。
雖然 Graphcore Bow IPU 是一款更大的 HPC 晶片,但頂部晶片不是前沿邏輯,而是用於供電的被動電容晶片,因此其良率應該相當高,而且矽片更便宜。 W2W 的另一個缺點是頂部晶片和底部晶片的尺寸必須一致,因此這限制了異質整合選項的靈活性。
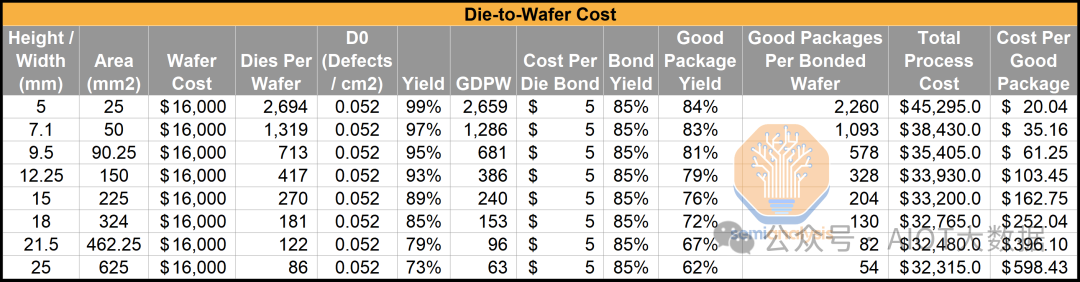
成本有多種影響因素。主要因素包括晶圓成本、D0(缺陷密度)和鍵結良率。每個因素都可能導致成本增加或降低。請注意,這些是範例數字,用於強調這一點。請勿使用下表,因為它未顯示鍵合的實際成本。如需了解當今產品的實際成本,請聯絡我們以取得 AMD MI300X 成本報告或 Zen 3、Zen 4 和 Zen 5 混合鍵結成本報告。
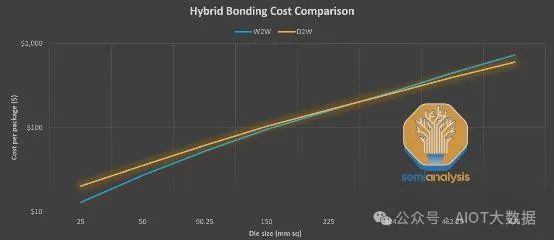
可以看出,D2W 在小型晶片上的成本更高,但對於大型晶片,情況則相反。 W2W 比較昂貴。能夠測試和黏合已知良好晶片 (KGD),而不是冒著缺陷堆積和浪費良好矽片的風險,這一點至關重要,這也是為什麼晶圓上晶片 (D2W) 是第一個實現產品化的方法。它可以處理較差的產量,但仍具有商業上可行的產品。
為了突破限制,我們需要採用 D2W。 D2W 鍵結更具挑戰性。在完成晶圓分類後,KGD 從頂部晶圓分離出來,並透過拾取和放置工具單獨附著到底部晶圓上。這在鍵合方面更具挑戰性,因為每個晶圓都需要更多鍵合步驟。這些額外的步驟會引入更多的顆粒污染,尤其是來自晶片分離和拾取和放置過程中鍵合頭的移動。
D2W 可以是一個「集體」過程,其中 KGD 被對準並首先臨時鍵結到重構的載體晶圓上。然後將重構的載體晶圓鍵結到基片上進行實際預鍵合。這是為了像 W2W 一樣將對準和鍵結分開,並允許在最終預鍵合之前進行清潔步驟以去除任何已累積的污染物。缺點是涉及額外的步驟,額外的 W2W 鍵合步驟會增加對準誤差的可能性。
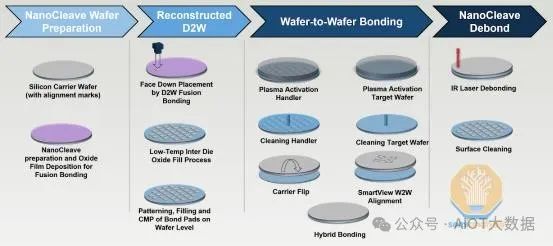
這實際上是一個簡化的流程,因為底部晶片也可以在載體晶圓上重建。因此,頂部和底部晶片都是從原始矽晶圓上切割下來的,並對 KGD 進行分類。兩組晶片都黏合到各自載體上的精確位置。然後,使用 W2W 製程將 2 個載體晶圓黏合。這是在 TSMC SOIC 中完成的。因此,每個 AMD 3D V 快取晶片(底部 CPU 晶片到載具、3D V 快取晶片到載具、2x 虛擬矽到載具)和晶圓對晶圓使用 5 個黏合步驟。
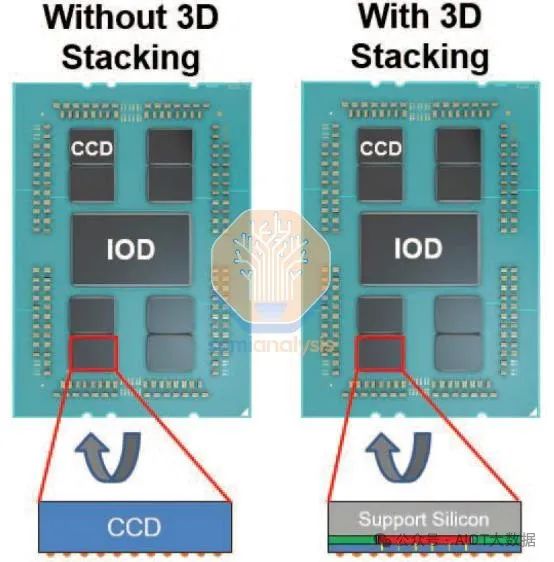
重構製程也可用於更極端的異質整合選項。英特爾在 IEDM 2022 上展示了「準單晶片 (QMC)」。他們展示的 QMC 應用的一個例子是頂部和底部各有 2 個異質整合晶片的封裝。對於頂部和底部,每個晶片都連接到載體晶圓上。然後用厚無機氧化物(如 SiO2)模製晶圓。進行 W2W 鍵結。然後將模製的晶片單片化並連接到封裝基板上以完成流程。
請注意,重建的區域內可能存在 TSV。
直接 D2W 鍵結是將單一晶片直接放置在目標晶圓上進行預鍵合。直接 D2W 不太成熟,但由於流程簡化,似乎未來直接 D2W 會得到更多使用。集體 D2W 的一個好處是可以進行清潔,然後直接送入對準室以減少污染。最近推出了 D2W 叢集工具(將在下文討論),它可以重現這種流程,從而降低這種集體過程的好處。此外,由於對準變得更具挑戰性,D2W 更適合更細的焊盤間距,因此消除 W2W 步驟是有好處的,因為 W2W 步驟會在 W2W 步驟中引入額外的錯位風險。
鑑於 D2W 混合鍵合的製程挑戰和成本,目前的應用有限。 AMD 是 2022 年的首批採用者,並且至今仍是唯一採用者。我們將在稍後討論未來的應用、各公司的採用率、製程步驟數等。
需要注意的一點是,W2W 在對準方面遠遠領先於 D2W,因此如果您的設計不是異質的,並且晶圓良率足夠高,那麼它實際上將是一種更精確、良率更高的工藝。這種更精細的間距還將解鎖許多 D2W 尚未突破的新用例。
混合鍵合製程
接下來讓我們更詳細地了解 D2W 和 W2W 的流程。

TSV 形成
正如我們上面提到的,TSV 需要為封裝中的所有晶片提供電源和訊號。想像一下傳統的倒裝晶片封裝。晶片只需要一側的互連即可接收電源並與封裝基板進行資料通訊。此互連層具有連接到被動佈線層(也稱為“金屬層”或“線路後端”/BEOL)的凸塊,這些凸塊為切換和處理資料的電晶體層提供電源和訊號。
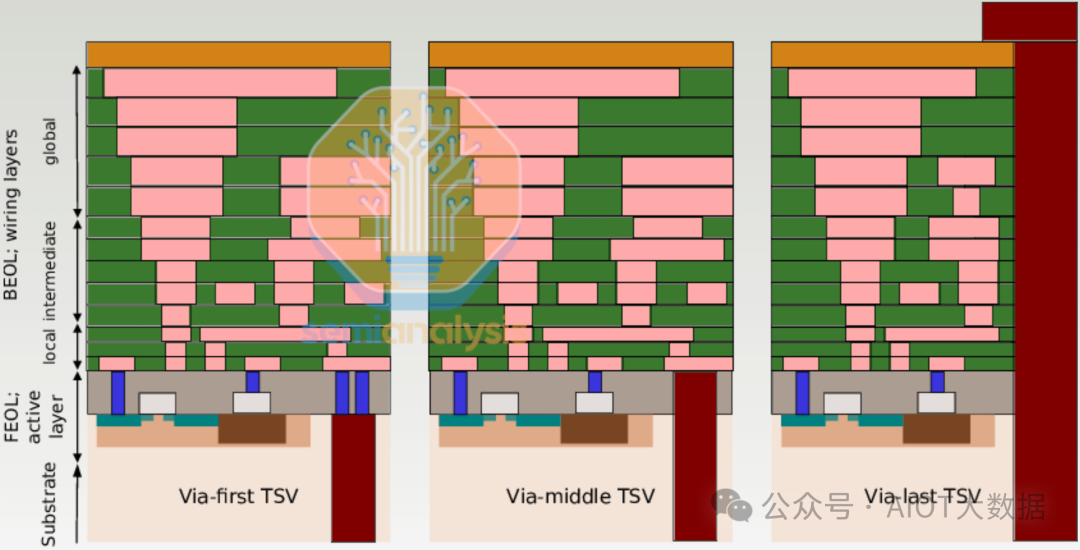
對於 3DIC,底部的晶片需要能夠與其下方的封裝基板以及其上方的晶片進行通信,因此晶片的兩側都需要互連。這就是 TSV 發揮作用的地方。 TSV 有多種變體,具體取決於它們在流程中的製造時間。 TSV 可以是「先通孔」的,即在電晶體層之前先在矽片中製造;「中通孔」的,即在電晶體層完成後、金屬層之前製造;或「後通孔」的,即在 BEOL 之後。
對於 3DIC 來說最常見的是「中間通孔」方法,因為 TSV 運行在金屬層之間,穿過電晶體層並顯露出晶片的背面,這樣現在晶片兩側都有一層互連,我們將對此進行描述。
我們在這裡討論了 TSV 流程,但將在本報告中重新進行概括。
晶圓上塗有光阻,然後使用光刻技術進行圖案化。然後,使用深反應離子蝕刻 (DRIE) 將 TSV 蝕刻到矽中,以在晶圓深處形成高縱橫比溝槽,但不會穿透整個晶圓。使用化學氣相沉積 (CVD) 沉積絕緣層 (SiOX、SiNx) 和阻擋層 (Ti 或 Ta)。這些層用於防止銅擴散到矽中。然後,使用物理氣相沉積 (PVD) 沉積銅種子層。此種子層沉積在溝槽中,然後使用電化學沉積 (ECD) 填充溝槽。這形成了 TSV。但是,該過程尚未完成,因為背面的通孔尚未露出。為了露出 TSV,TSV 的背面被拋光,在某些情況下還被蝕刻以減薄背面並隨後露出 TSV。完成後,晶圓可以繼續形成 BEOL。
TSV 的形成並非易事,而且可能非常耗時,尤其是由於需要深度蝕刻。我們了解到,TSV 的形成是 HBM 和 CoWoS 生產的瓶頸。有些客戶從矽中介層轉向 CoWoS-R 的原因之一是為了避免矽中介層中昂貴的 TSV 製程。
混合鍵層形成
在晶圓的鍵合界面之後,在晶圓的 BEOL 頂部製造混合鍵合層。無論是 W2W 還是 D2W,這都是相同的。這是一層用細間距銅通孔圖案化的介電膜。電介質,通常是碳氮化矽 (SiCN),透過 PECVD 沉積。然後形成焊盤。使用光刻技術對銅焊盤的孔進行圖案化並蝕刻掉。沉積阻擋層和種子層,然後使用典型的銅鑲嵌工藝鍍銅。
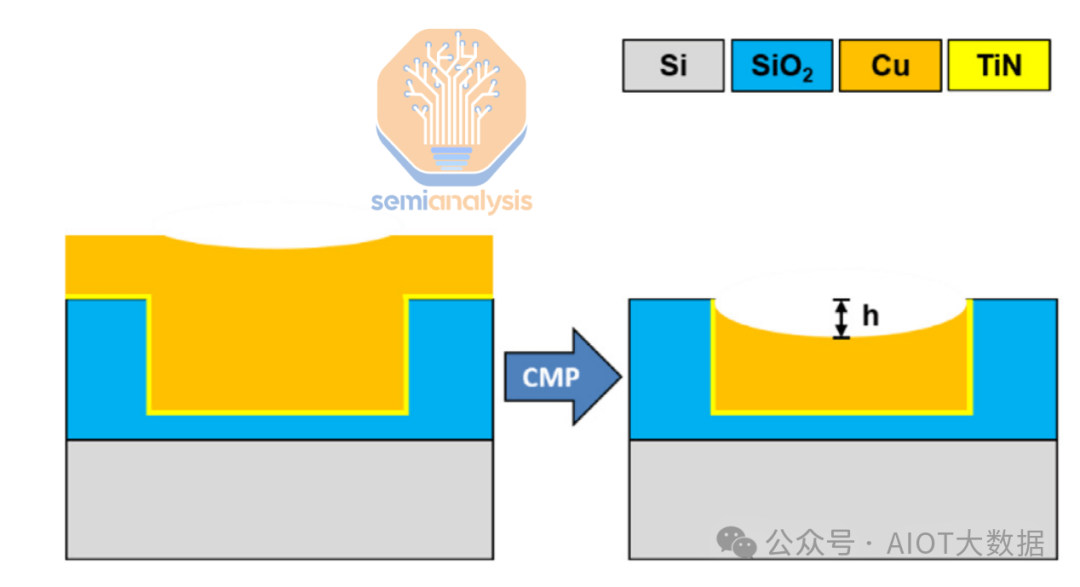
然後,進行 CMP 步驟以研磨和平滑電介質表面,並獲得正確的銅輪廓。銅墊的一個顯著特徵是它們凹陷至約 1 微米間距。如前所述,光滑的表面對於形成良好的黏合至關重要。電介質的粗糙度必須控制在 0.5nm 以內,銅墊的粗糙度必須控制在 1nm 以內。
HB 介面的一個特點是銅墊最初凹進介電層下方約 5 奈米。這是為了確保在退火過程中銅不會妨礙初始介電層-介電層鍵結。如果銅凹進得太深,則 Cu-Cu 鍵結可能無法正常形成。
在對銅和其他金屬進行 CMP 時,由於過度拋光以及金屬和電介質的軟度不同,經常會出現凹陷。雖然這不是理想情況,但這種現象並不嚴重,可以解決。需要控制凹陷的確切輪廓,以防止在黏合過程中出現銅過度生長/不足的情況。
為了獲得正確的凹陷輪廓,需要結合低和高 Cu 去除漿料的多個 CMP 步驟。 CMP 是混合鍵結實現非常光滑的表面和最佳輪廓的關鍵工藝。
在 ECTC 上,索尼展示了當間距減小到 1 微米時,讓銅突出比讓銅凹進效果更好。
晶圓分類/分離
僅對於 D2W,執行晶圓分類,並將 KGD 單獨化並在載體晶圓或膠帶框架上重組,以便進一步處理。如上所述,HB 為傳統晶圓分類過程帶來了新的複雜性。晶圓分類涉及用探針探測晶圓凸塊或焊盤以進行電氣測試。
探測會在銅焊盤表面造成少量損壞,從而破壞 CMP 製程中表面的光滑度。雖然對焊盤的損壞很小,在大多數情況下通常可以接受,但 HB 對少量地形變化非常敏感,因為這些變化會影響鍵合品質。解決此問題的一種方法是在初始 CMP 中對此進行補償,然後進行另一輪 CMP 後探測以拋光探測造成的任何損壞。
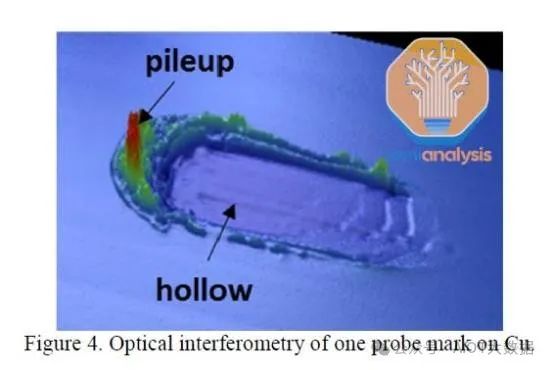
對於單片化/切割,一個問題是製程中產生的顆粒。刀片切割通常不使用,因為它最髒:會產生大量顆粒並造成大量產量損失。雷射切割和等離子切割比刀片切割更受歡迎,因為它們是更清潔的工藝,但仍會產生顆粒物。等離子切割是最極端的方法,其機制類似蝕刻掉分隔晶片的劃線。然而,考慮到蝕刻整個晶圓所需的時間,這種方法的產量要低得多。

Disco 是這個領域的領導者。自從我們報道他們以來,他們的股票已經上漲了兩倍多。
一種緩解技術是先在晶圓上塗上一層保護層塗層。顆粒落在保護層上,可以在剝離保護層時與保護層一起被移除。雖然這有助於解決分割過程中的顆粒問題,但可能會有保護層的殘留物,剝離過程也可能對 HB 層造成一些表面損壞,從而增加表面粗糙度。
等離子活化與清潔:
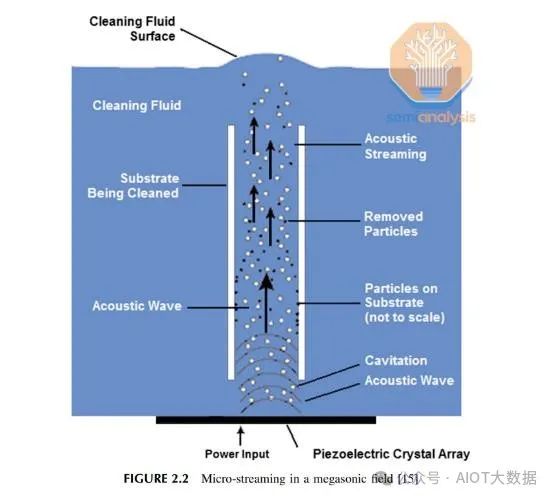
現在對 2 片晶圓進行處理,為黏合做好準備。它們用 N2 等離子體處理以激活表面。等離子處理改變了表面的特性,增加了表面能,使其更親水性。使兩個表面都更親水可以使表面促進氫鍵。這有助於實現下一步在室溫下發生的初始弱電介質-電介質預先黏合。
處理後,進行最後的清潔以去除任何累積的顆粒。在鍵合之前,重要的是,傳入的晶圓應盡可能乾淨。清潔需要徹底,但也不能損壞,以保持 HB 介面的完整性。最好的方法似乎是使用去離子水基清潔,輔以超音波。使用洗滌器或等離子清潔可能會造成太大的損害和/或引入污染物。
黏合
現在開始鍵結步驟。更準確地說,它更像是“預鍵合”,因為此步驟僅形成初始電介質-電介質鍵,而這只是一種弱范德華鍵。我們將分別介紹 W2W 和 D2W 方法的流程。
W2W 鍵合
使 W2W 鍵合良率更高的原因是對準和鍵合步驟是分開的。首先是對準步驟。 W2W 對準有多種技術。過去,人們會使用紅外線掃描儀來檢查兩個晶圓之間的對準。限制在於一個晶圓必須對紅外線透明。這對 CMOS 晶圓不起作用,因為紅外線無法穿透金屬層。
EVG 在 W2W 鍵結領域佔據主導地位,擁有其專利的 SmartView 對準技術。有 2 個相機相互校準,一個放在目標晶圓上方,一個放在下方。固定頂部晶圓的卡盤移動,以便底部相機可以識別對準標記,並且系統記錄對準標記的位置。頂部晶圓縮回,然後底部晶圓在相機之間移動,直到頂部相機可以識別對準標記。對準器現在可以透過計算 2 個對準標記的相對位置來對準 2 個晶圓。為了幫助保持準確性和控制力,晶圓彼此非常接近(50 微米以內),並且卡盤僅在 X 和 Y 平面上移動,Z 軸(垂直)沒有移動,直到預鍵合。
對準後,將晶圓移入鍵結室,在那裡以較小的壓力將它們壓在一起,持續約 20 分鐘以形成初始鍵合。
黏合後檢查可透過聲學方法在現場完成,如果對準不充分,則也可重新黏合。
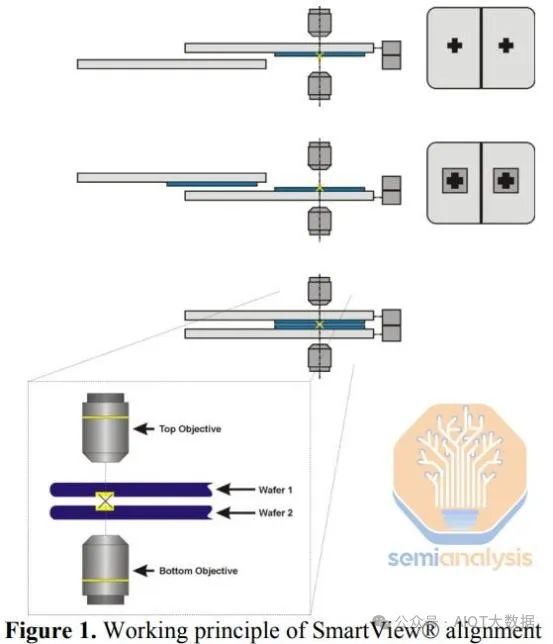
在 W2W 工具中,有一個單獨的腔室用於執行對準。一旦頂部和底部晶圓對準,它們就會被移入鍵合腔室(處於真空中),在那裡用一點力將它們壓在一起,大約 20 分鐘後,初始預鍵合就形成了。 W2W 的關鍵在於它是一個更清潔的工藝,因為步驟更少。在對準和鍵合之前,可以清潔晶圓以去除大部分顆粒。晶片分離是顆粒污染的來源,僅在鍵合之後發生。
由於這是晶圓級工藝,因此對準步驟也有更多的時間,因此較長的對準時間不會像晶片級工藝那樣對產量造成太大影響。腔內也沒有太多移動,因此腔內產生的污染物較少。目前,W2W 鍵合機可以實現50nm 以下的對準精度。 W2W 鍵合已經是一種成熟的工藝,而且成本並不高。證據是,我們看到它被廣泛應用於大眾市場產品中,例如索尼、Omnivison 和三星的圖像感測器,以及長江儲存、西部數據和鎧俠的 NAND。
D2W 黏合
D2W 黏合是透過拾取和放置工具完成的。
底部目標晶圓位於晶圓夾盤上。要黏合的晶片面朝上放置在膠帶框架上。翻轉臂收集單一晶片並將其翻轉,使晶片背面朝上放置在翻轉器上。上方有一個黏合臂,它使用黏合頭上的真空吸力拾取翻轉的晶片。
CoWoS-S(主要變體)的關鍵製造步驟
CoWoS 是台積電的「2.5D」封裝技術,其中多個主動矽片(通常的配置是邏輯和 HBM 堆疊)整合在被動矽片中介層上。中介層充當頂部有源晶片的通訊層。然後將中介層和主動矽片連接到包含 I/O 的基板上,以放置在系統 PCB 上。 CoWoS是 GPU 和 AI 加速器最受歡迎的封裝技術,因為它是共同封裝 HBM 和邏輯以獲得最佳訓練和推理工作負載效能的主要方法。
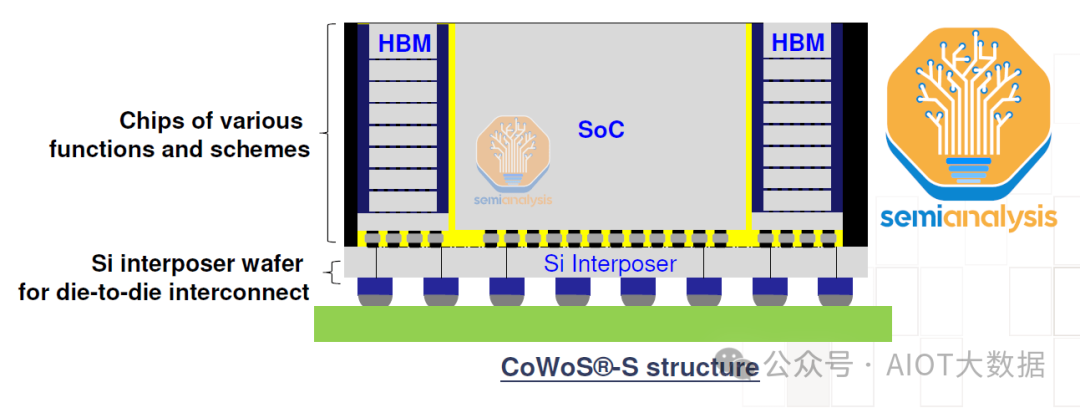
我們現在將詳細介紹 CoWoS-S(主要變體)的關鍵製造步驟。
矽中介層關鍵製程步驟
第一部分是製造矽中介層,其中包含連接晶片的「線路」。這種矽中介層的製造類似傳統的前端晶圓製造。人們常聲稱矽中介層是採用 65nm 製程技術製造的,但這並不準確。 CoWoS 中介層中沒有電晶體,只有金屬層,可以說與金屬層間距相似,但事實並非如此。
這就是為什麼 2.5D 封裝通常由領先的代工廠內部完成,因為他們可以生產矽中介層,同時還可以直接使用尖端矽。雖然 ASE 和 Amkor 等其他 OSAT 已經完成了類似於 CoWoS 或 FOEB 等替代方案的先進封裝,但他們必須從 UMC 等代工廠採購矽中介層/橋接器。
矽中介層的製造始於取一塊空白矽晶圓並製作矽通孔 (TSV)。這些 TSV 穿過晶圓以提供垂直電氣連接,從而實現中介層頂部的主動矽片(邏輯和 HBM)與封裝底部的 PCB 基板之間的通訊。這些 TSV 是晶片向外界發送 I/O 的方式,也是晶片接收電源的方式。
為了形成 TSV,需要將光阻塗在晶圓上,然後使用微影技術進行圖案化。然後使用深反應離子蝕刻 (DRIE) 將 TSV 蝕刻到矽中,以實現高縱橫比蝕刻。使用化學氣相沉積 (CVD) 沉積絕緣層 (SiOX、SiNx) 和阻擋層 (Ti 或 TA)。然後使用物理氣相沉積 (PVD) 沉積銅種子層。然後使用電化學沉積 (ECD) 用銅填充溝槽以形成 TSV。通孔不穿過整個晶圓。
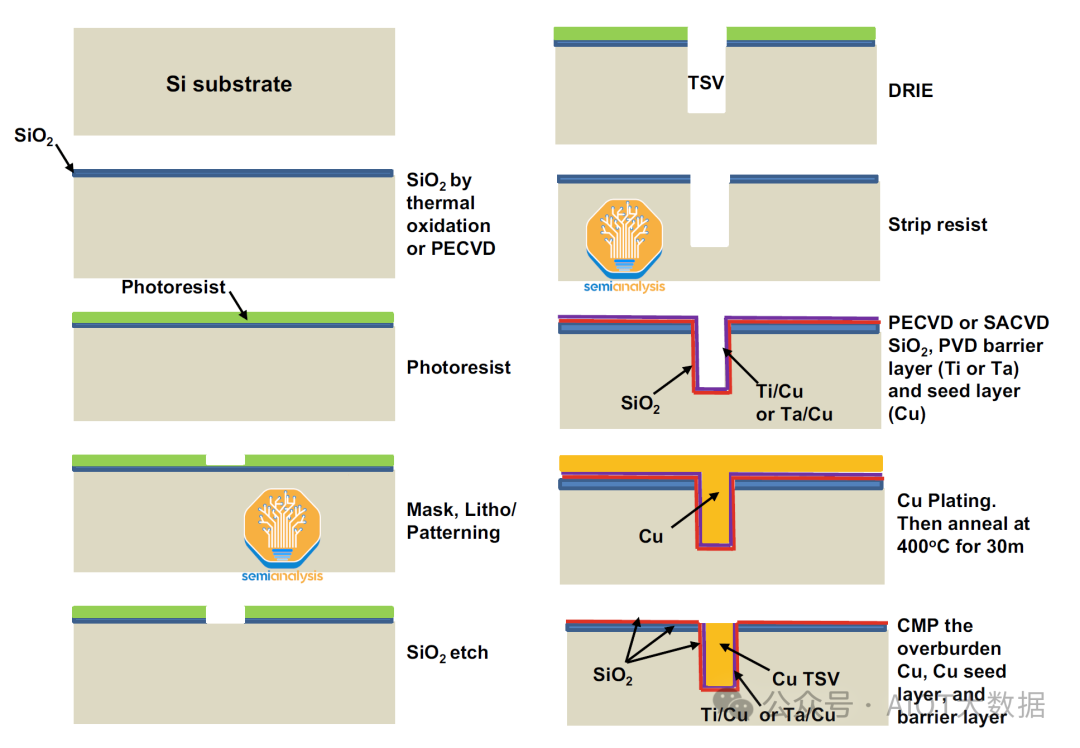
TSV 製造完成後,在晶圓的頂部形成重分佈層 (RDL)。將 RDL 視為將各種主動晶片連接在一起的多層線路。每個 RDL 都由一個較小的通孔和實際的 RDL 組成。
透過 PECVD 沉積二氧化矽 (SiO2),然後塗上光阻,使用微影技術對 RDL 進行圖案化,然後使用反應離子蝕刻去除 RDL 通孔的二氧化矽。此過程重複多次,以在頂部形成更大的 RDL 層。
在典型的配方中,鈦和銅被濺射,銅則使用電化學沉積 (ECD) 進行沉積。然而,我們認為台積電使用極低 k 電介質(可能是 SiCOH)而不是 SiO2 來降低電容。然後使用 CMP 去除晶圓上多餘的鍍層金屬。這主要是標準的雙鑲嵌工藝。對於每個額外的 RDL,都會重複這些步驟。
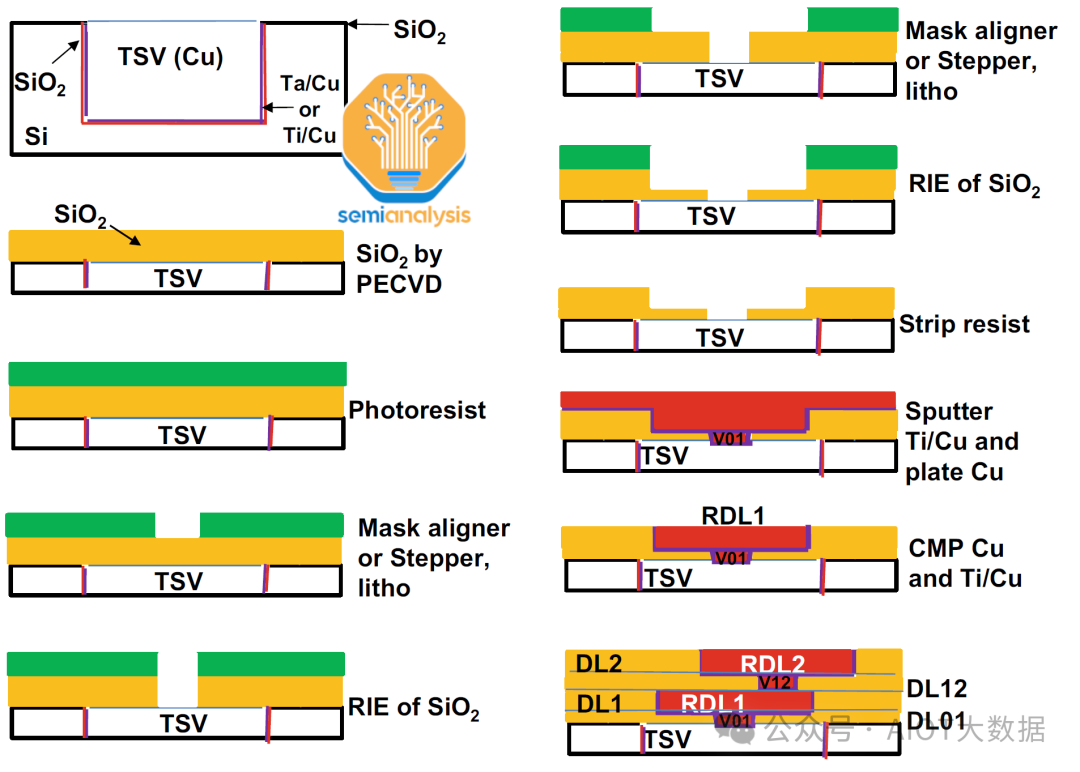
在頂部 RDL 層上,透過濺鍍銅形成凸塊下金屬化 (UBM) 焊盤。塗上光阻,用光刻技術曝光以形成銅柱圖案。對銅柱進行電鍍,然後用焊料覆蓋。剝離光阻並蝕刻掉多餘的 UBM 層。 UBM 和隨後的銅柱是晶片與矽中介層連接的方式。
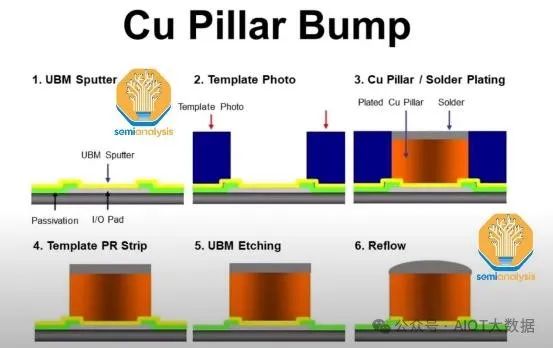
晶圓上晶片關鍵製程步驟
現在,使用傳統的倒裝晶片回流焊接製程將已知良好的邏輯和 HBM 晶片連接到中介層晶圓上。在中介層上塗上助焊劑。然後,倒裝晶片接合器將晶片放置在中介層晶圓的焊盤上。然後將放置了所有晶片的晶圓放入回流焊爐中烘烤,使凸塊焊料和焊盤之間的連接固化。清除多餘的助焊劑殘留物。
然後用樹脂填充主動晶片和中介層之間的縫隙,以保護微凸塊免受機械應力。然後再次烘烤晶圓以固化底部填充物。
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
接下來,用樹脂模製頂部晶片以將其封裝起來,並使用 CMP 來平滑表面並去除多餘的樹脂。現在將模製的中介層翻轉並透過研磨和拋光減薄至約 100um 厚度,以露出中介層背面的 TSV。
附著在中介晶圓頂部的頂部晶片和封裝儘管變薄了,但仍可以為晶圓提供足夠的結構支撐和穩定性,因此並不總是需要載體晶圓來支撐。
晶圓基板關鍵製程步驟
中介層背面鍍上 C4 焊錫凸塊,然後切割成每個單獨的封裝。然後使用倒裝晶片將每個中介層晶片再次安裝到積層封裝基板上,以完成封裝。
在下面的 Nvidia A100 橫截面中,我們可以看到 CoWoS 封裝的所有各種元素。
頂部是帶有 RDL 的晶片晶片和銅柱微凸塊,這些微凸塊與矽中介層正面的微凸塊粘合在一起。然後是頂部帶有 RDL 的矽中介層。我們可以看到 TSV 穿過中介層,下面每個 C4 凸塊有 2 個 TSV。底部是封裝基板。
請注意,A100 在中介層正面只有一面 RDL。 A100 的架構更簡單,只有記憶體和 GPU,因此佈線要求更簡單。 MI300由記憶體、CPU 和 GPU 組成,全部位於 AID 之上,因此需要更複雜的 CoWoS 佈線,從而影響成本和產量。
先進封裝的各大玩家的技術發展路線圖